
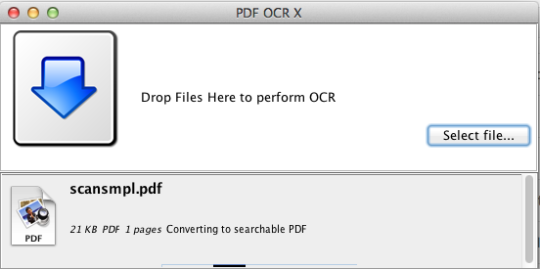
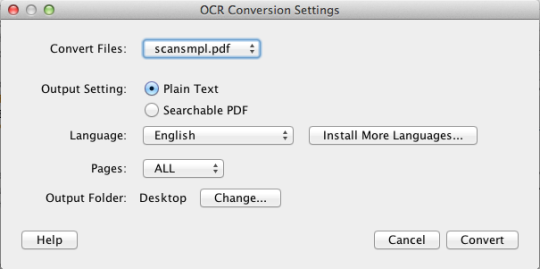
PDF OCR X to proste narzędzie do przeciągania i upuszczania dla systemu Mac OS X, które konwertuje pliki PDF i obrazy na tekst lub przeszukiwane dokumenty PDF. Wykorzystuje zaawansowaną technologię OCR (optyczne rozpoznawanie znaków), aby wyodrębnić tekst PDF (lub obraz), nawet jeśli ten tekst jest zawarty w obrazie. Jest to szczególnie przydatne w przypadku plików PDF i obrazów utworzonych za pomocą funkcji skanowania do pliku PDF w skanerze lub kopiarce zdjęć. Obsługuje ponad 60 języków dla OCR. Silnik OCR bazuje na Tesseract. Wersja społecznościowa obsługuje pojedyncze strony PDF (lub pierwszą stronę wielostronicowych plików PDF). Aby uzyskać obsługę wielu stron PDF, należy uaktualnić do wersji Enterprise.
Co nowego w tej wersji:
Wersja 2.1.1 dodaje obsługę Mojave i poprawia interfejs użytkownika na wyświetlaczach Retina.
Co nowego w wersji 2.0.8:
Naprawiono problem związany z obsługą niektórych plików PDF z rotacją.
Ograniczenia :
Wersja społecznościowa ogranicza się do jednostronicowych plików PDF i obrazów.




Komentarze nie znaleziono