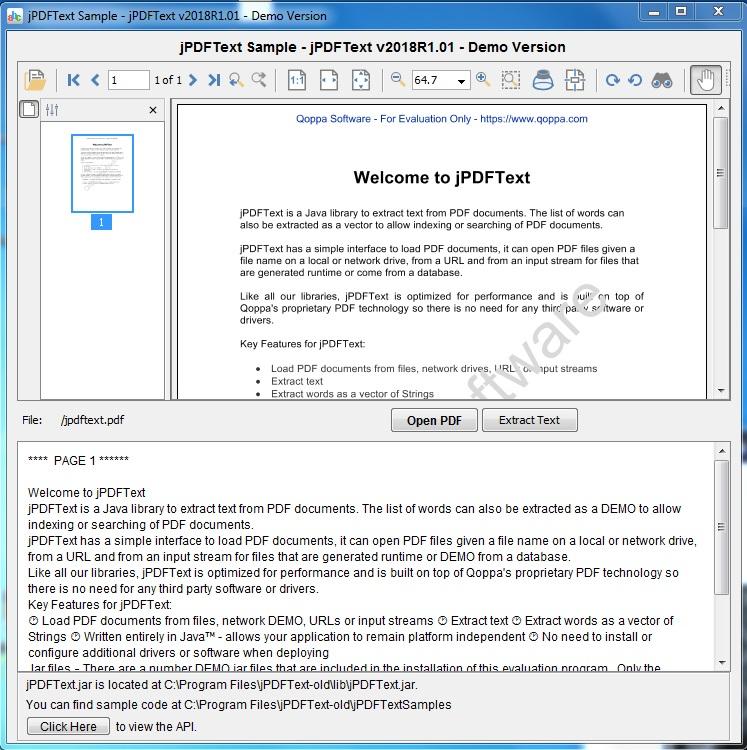
jPDFText to biblioteka Java do wyodrębniania tekstu z dokumentów PDF. Za pomocą jPDFText można przetwarzać dokumenty PDF, aby wyodrębnić zawartość tekstową do archiwizacji, przechowywania, wyszukiwania lub indeksowania. jPDTextext jest zbudowany na zastrzeżonej technologii PDF firmy Qoppas, dzięki czemu nie trzeba instalować żadnego oprogramowania ani sterowników innych firm. Ponieważ jest napisany w Javie, pozwala aplikacji pozostać niezależną od platformy i działać w systemach Windows, Linux, Unix (Solaris, HP UX, IBM AIX), Mac OS X i każdej innej platformie obsługującej środowisko wykonawcze Java.
Główne cechy:
Załaduj dokumenty PDF z plików, dysków sieciowych, adresów URL lub strumieni wejściowych.
Wyodrębnij tekst w logicznej kolejności czytania.
Wyodrębnij słowa jako wektor ciągów.
Działa na systemach Windows, Linux, Unix i Mac OS X (100% Java).
Nie ma potrzeby instalowania ani konfigurowania dodatkowych sterowników ani oprogramowania podczas wdrażania.
Testowany na JDK 1.4.2 i nowszych.


Komentarze nie znaleziono