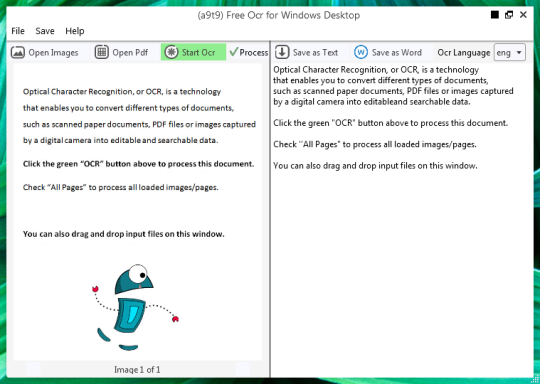
Darmowe oprogramowanie OCR, aby wyodrębnić tekst z plików graficznych i elementów PDF. Graficzny interfejs użytkownika (GUI) dla silnika Tesseract OCR.
Aplikacja jest prosta w instalacji i, co ważniejsze, darmowe, open-source i 100% adware i spyware bezpłatny.
Możesz otworzyć obrazu lub pliku PDF. Zawartość pliku źródłowego będą wyświetlane w lewym oknie. Jeśli dokument w więcej niż jednej strony, lub jeśli otwarte wielostronicowych dokumentów, za pomocą strzałek na dole, aby przełączać się między nimi,
Zaczynasz OCR, klikając zielony przycisk OCR, a zobaczysz wynik w drugim prawym oknie. Tekst wyjściowe mogą być zapisane w postaci pliku tekstowego lub dokumentu programu Word.
Niestety jakość konwersji nie jest tak wielka. Za scenę wykorzystuje open-source silnika OCR Tesseract. Jakość waha się od języka na język. - Więc śmiało testu, jeśli jest wystarczająca dla potrzeb
Dla programistów i maniaków: The OCR bezpłatny dla pulpitu Windows jest narzędziem zasadniczo interfejs graficzny front-end (GUI) dla silnika Tesseract OCR. Pełny kod źródłowy jest dostępny (licencja GPL).
Silnik z oprogramowania OCR obsługuje następujące języka OCR: angielski, francuski, włoski, niemiecki, hiszpański, brazylijski portugalski i niderlandzki. Począwszy od wersji 3 może rozpoznać arabski, bułgarski, kataloński, chiński (uproszczony i tradycyjny), chorwacki, czeski, duński, holenderski, angielski, niemiecki (standardowe i skryptów Fraktur), grecki, fiński, francuski, hebrajski, hindi, węgierski, indonezyjski, włoski, japoński, koreański, łotewski, litewski, norweski, polski, portugalski, rumuński, rosyjski, serbski, słowacki (standardowe i skrypt Fraktur), słoweński, hiszpański, szwedzki, tagalog, tamilski, tajski, turecki, ukraiński i wietnamski.
Komentarze nie znaleziono